

We have to think interdisciplinary. This is why The Law Technologist will start a series of interviews to reflect different views on the current developement of AI (algorithmic decision making).
Please read the first one with Dr. Detlef Steuer, Lecturer at the Helmut Schmidt University in Hamburg and Head of the mathematics laboratory. He shares his view on data driven Algorithms, errors in reading statistics, his review of the ethical guidelines developed by the EU commission, red lines of automation and why he thinks data science needs to grow to a proper profession.
While preparing this interview
COVID-19 overwhelmed the world.
Hello Detlef, and welcome to the first interview of our multidisciplinary approach to a better understanding of AI.
Like all of us, you work from home these days, in this case in your sunny garden. Please share with us your impressions under this special and abnormal situation.
Hello Ramak! From a data scientist’s perspective, these are interesting times. Never before have I been asked by a neighbour about the possible future development of a time series. In the beginning one had to explain what an exponential curve means. Today many people have an idea of what a logistic curve looks like. Suddenly it is a respectable art to make sense out of numbers.
A look at the available data showed and still shows how important data quality is. Without suitable tests, we cannot reliably estimate the mortality rate because we do not have a reliable denominator and therefore no reliable forecast. If, as in Germany, the figures are collected in an unsystematic way on weekends, these figures are of little use.
On the other hand, we have found out what kind of Orwellian monitoring is possible with current technology. South Korea published clear names of COVID-19-infected people together with their localization history, so that everyone could see whether he or she was in close contact. Of course, one cannot criticize this in the current emergency, but to see what is possible makes me shiver. You lawyers must be very, very careful and vigilant to save freedom in our free societies from COVID-19!
One last thought: compare these two curves.
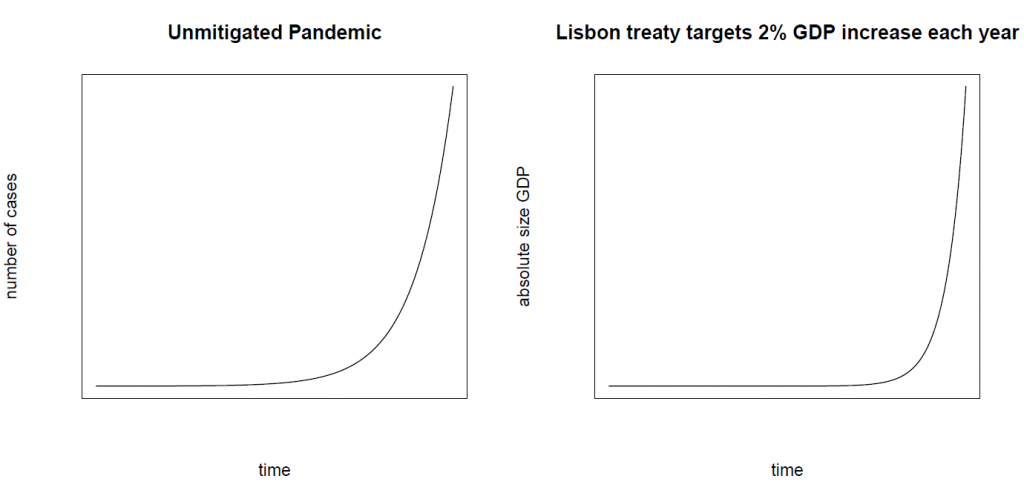
The underlying relationship over time is the same. I deliberately omitted the time frame, because 2% growth per year is obviously much lower than the rates observed in the current pandemic, which are around 10% or more per day.
However, when we talk about a relative increase in GDP per year, we are trying to impose exponential growth in GDP. And GDP still measures the consumption of resources in our small world. So such exponential GDP growth consumes finite resources, just as an unchecked pandemic infects people.
Right now, the whole world is fighting as hard as it can to stop the exponential growth of the pandemic. Perhaps once the current crisis is over, we should reconsider our way of life and try to stop the exponential use of our resources.
There is only one world, and sustainable and exponential do not fit together.

Back to Covid-19 – free topics: Let us know what you do and what is important to you in life and at work.
My work has diverse facets. Teaching and giving lectures in data analysis and programming of R at our department is as much a part of it as supporting PhD students with computer-based statistics or pure statistical problems. For the R project (www.r-project.org) I am responsible for the German Translation. Also the preparation of packages for R for the OpenSUSE Linux distribution is part of my regular work for this project. Managing the centralized and local IT resources for the department is another part of my work. My research is currently focused on Responsibility of scientists towards society, namely data scientists.
The most important aspect, from a scientific and social point of view, is the urgent action we need to take to control the data collection of our lives and consequently the algorithms that analyze all this data.
The technological advances of recent years are breathtaking. In a sense, it can be said that analysis today is faster than real time. „The machines“ or „algorithmic systems“ are drawing conclusions faster than humans can comprehend the inputs. The most frightening single point of failure I can imagine for the application of data science, statistics or AI, whatever you want to call it, is the inevitable automatic reaction to signs of attack by one of the superpowers with hypersonic missiles.
In the 1980s, as we know today, a Russian officer literally saved the world because his human reasoning found the observed attack pattern illogical for a first strike with nuclear weapons. In a few years, new superfast weapons will leave no time for human intervention. Defense must be implemented automatically. Some sophisticated models will monitor the sky day and night. And as any data scientist knows, one day those models will fail.
In an algorithm-driven society, data plays a major role. Is data analysis overrated as a problem solver and a great opportunity?
We can only learn from good data. At the moment we simply collect all the data at our disposal in an unorganized way and try to learn from it. Of course however, there are problems where collecting a lot of data can help. But collecting data about individuals can easily interfere with the right to privacy. I am sceptical whether all the promises and hopes associated with data analysis can be fulfilled.
People tend to get statistics wrong. As an expert on statistics, can you name some examples and tell us why?
We as humans have some problems with numbers, especially with probabilities.
First, we are more or less incapable of intuitively grasping nonlinear events (this was at least the case before the pandemic). It seems that intuition has been sufficient for linear models in the last few million years of evolution.
Second, we are so poor at estimating the real world relevance of very low probabilities.
Third, we have a very poor intuition for conditional probabilities. This last point is perhaps the most important in the current political discussion.
Is the data as neutral as people tend to think?
Who thinks that data is neutral? The only data I would call neutral is data that would be useless even if your worst enemy had access to it.
Take biometric databases, for example. A collection of fingerprints, such as the one used in India to regulate access to some of the state’s welfare. This data is only neutral as long as access to the database is error-free and all data in the database is correct. There are reports that some people are starving because the database has somehow lost the ability to recognize their fingerprints. Not exactly neutral. But we don’t need to look that far. Just think of the price tag on a consumption data set.
The people who buy those records obviously don’t think that the data is neutral. I would consider technical data neutral, but data about people?
Which data is good data? Is more always better?
First of all you have to look at how the data is generated. In the last century, surveys were conducted by calling random numbers from the telephone directory and trying to form a representative sample of a population. This worked reasonably well until the mobile phone took over. First, the younger generation disappeared from the pool of respondents found through phone calls. Nowadays, it would probably be a difficult task to form a representative sample with only fixed lines.
Secondly, it must be asked whether the data are good for the purpose of the task at hand. You really have to think carefully before feeding the data into a random algorithm, what are the possible errors in the uncontrolled data collected.
Look at the famous example of Amazon trying to automate its recruitment process. It seemed reasonable to use all successful applications from the past, use some AI and find an automatic evaluation of new applicants. It turned out that the AI rejected all female applicants completely. It did so based on the simple fact that most of the former applicants for the job were men, as were the successful applicants. Therefore it was easy for the AI to use „gender“ as a classification criterion for successful applicants. The data used was not suitable for the job! And more data of this kind would not have helped.
The data must be carefully selected for the task at hand, if possible in a very controlled (planned) environment.
In your opinion, data science is not yet a real profession. What exactly do you mean by this and what would be the benefit of professionalising data science?
This question is difficult to answer in just a few sentences. Usually there are a number of slides reserved for exactly this question. But I will try.
Data scientists have very different backgrounds at the moment. All the jobs of data scientists were created because data was available in overwhelming amounts. As the amount of data grows faster and faster, there is an enormous need for data scientists, but there are still only a few highly qualified specialists available. Consequently, many people with an education in similar fields such as mathematics, physics, etc. are now working as data scientists. These have often learned their ML/AI tools in short crash courses.
Thinking about ethical questions when using the tools is (mostly) not part of such crash courses.
Moreover, the application of data science is mostly unregulated. Public scandals like Cambridge Analytica or the relentless data collection of Facebook, Google and Amazon give the impression that data science does not work for the common good. The analysis of more and more data will increasingly affect the lives of all people.
To have confidence in data-driven decisions about oneself through applied data science, one must be able to recognize the expertise of the data scientist who supervises the application of that algorithm. Such trust can only be generated if data science creates a certain professional ethic that, in my opinion, considers the consequences of every decision made by data scientists to be essential.
The sky won’t turn blue immediately when data science becomes a proper profession, but perhaps it will stop raining a little more often!
Starting from an accepted professional ethic as the cornerstone for a profession called data science, education would be standardized in the long run on some fundamentals. An important side effect would be a better possibility to fight against charlatans in the field of data science.
Trust is always the most important aspect.
How is it that technicians often seem to lack a sense of responsibility for their work or an interest in its ethical implementation? Is it a lack of perception of the impact of their work?
I work in the academic field, so I only know from conversations with colleagues who work in companies.
A very important aspect is the lack of time. Most data scientists have to submit their reports without having much time to think about the impact of an analysis outside their own management. So my judgement of colleagues is not as harsh as your question suggests. This is an aspect that I believe could be improved by professionalising data science.
The EU Commission’s High Level Group on AI has recently published ethical guidelines for trustworthy AI as well as investment and regulatory recommendations. What is your opinion? What is missing, what is positive?
The strong priority given to human rights and the law system in general is positive. However, the second document talks too much about the opportunities (for companies) and too little about the threats (for individuals and society). There are no clearly defined red lines.
Indeed, the EU Commission has refrained from formulating red lines, only areas of concern such as profiling or social scoring are mentioned. What are your red lines?
My red line is the delegation of the making of irreversible decisions about people to algorithmic systems. There must always be a way to challenge the judgment that is directly affecting an individual (steps in this direction are prescribed in GDPR legislation).
It is my understanding that the consequences for the automation of decision making are serious. To challenge an automatic decision, the process must either be human understandable (interpretable machine learning is still in its infancy and I am not sure if it will ever work well enough) or easily overruled by a human.
If a person overrides an automatic decision, no pressure should be put on that person. This is just a dream, I know. Everybody wants to save money by the use of AI, so there will be a lot of pressure to follow the judgement of the AI. Otherwise, it’ll be futile.
It follows from this immediately that at least a permanent control of each of these systems must be implemented to find anomalies or flaws in the algorithms. If such a control is impossible due to the nature of the task, e.g. if an algorithm decides whether or not your employment office will spend more money on your training to improve your chances (in Austria or Poland), then the use of AI for such tasks should be excluded unconditionally. You can detect such a situation relatively easily.
If the application of an automatic decision making system leads to a self-fulfilling prophecy, the system is not suitable for the task at hand.
The focus must always be on the welfare of the individual, not on the chances of earning money through the data transmission of that individual. This will probably be a hard fight.
In your opinion, how would it be possible to assume more responsibility and accountability for technical development?
In my opinion, this cannot be done in a technical way. It has to be done through a social consensus on the red lines mentioned above. It will take time, but it is feasible.
Look at the historical data on road accidents. Fifty years ago, there were almost 20.000 fatalities per year in West Germany, today we have about 4.000 fatalities for the whole country.
This because, on the one hand, laws were introduced and, on the other, the public could see the effectiveness of these laws. There was great resistance when a limit on alcohol consumption while driving was introduced or when the compulsory seat belt was introduced. When we look back, we now think everyone who drove with 2 per mil or without a seat belt was crazy. Social perception has changed completely. We will probably see similar measures against mobile use while driving in our lives. So it is possible to regulate habits.
For data science, the „Pearl Harbour Event“ was the Cambrigde Analytica scandal. Suddenly there was evidence (or at least a strong belief) that uncontrolled digital data can be used to influence a Western society at the state level, not just at the individual level. Suddenly, ideas for regulation emerged.
I hope that this is only the beginning of a rapid departure from the times of the gold rush to a society where data security and sustainability are paramount.
Do we have an alternative to a future of human micro-profiling and surveillance? Can we free the further development of useful technology from the hunger for more and more data?
I would like to give two answers to this question. The first is the optimistic answer from a bird’s eye view. Of course! We just need to act together at all levels of society. We need data scientists, computer scientists, statisticians, legislators and lawyers, some philosophers and artists who join forces to use all our powerful new tools for the benefit of humanity. That IS possible and it has to be done.
There is a flip side to this answer. It does not produce real action. Besides, if you look around, the social movement against pervasive surveillance is not visible at the moment. So here comes a second possible answer.
We have to accept and realize that every act of data collection bears the root of a possible abuse within itself. Just as it provides opportunities for new insights. The only data that is never abused is data that is not collected.
For the individual, the risks can be mitigated if data collection is conducted anonymously. „Differential privacy“ as a mathematically proven way to prevent to de-anonymize data sets. The problem of this proof applies only to really sparsely collected data, and moreover one must trust the collector to have implemented the privacy part correctly. Nevertheless, there are works on data collection and on the elimination of the possibility to identify the data source.
Another major risk is the combination of many databases to gain insights on individuals and society. A lot of money is earned in this area, but it is far too dangerous to leave such a combination of data unsupervised and unregulated. I am sure that after a few more scandals laws will appear.
On the practical side, we as citizens must handle our data more responsibly. We give away too much to gain too little. Think, for example, of one of the routing services, let’s call it „maps“, which everyone uses.
If you now offer your location data on „maps“, they will save your location on their servers. In return, we receive very useful traffic information in real time. But think about it for a moment. The „Maps“ servers know exactly when your home is left alone. Where you go in the evening. Every night. You don’t even have to store an identifier to know where you live, because all your routes start and end at the same point. Combine that with commercially available address data and you’ll be deanonymised in a second. You do not want your worst enemy to know about such data collections. They should simply not exist if they are not needed for the service offered.
In order to improve the situation, the „maps“ could omit the first 5 minutes of each trip before the data is stored. Suddenly you can use the service and you are out of turn again. That was easy for the beginning.
All the hype is about monetizing every bit of data you can get. That’s why tough rules on data collection, use and re-use should be translated into legislation to save our individual freedom and support such privacy-driven improvements.
As long as that does not happen, the citizens must show that they care. Turn off the location data when you don’t need it. Use only services with clearly defined privacy rules. This is a bit uncomfortable at the start. It helps to think of the „worst enemy“: do you want to share your data with him or not?
Note that I have picked the maps example and did not even started with the trendy „intelligent assistants“.
They are always „on“ and always listening.
As a statistician I’m hungry for data, of course. But I’m convinced that any useful services can be implemented respecting our individual right on our personal data. Every data-collection must be a real opt-in, not just the typical click-through-information-nobody-has-time-or-interest-to read. Selling and reuse of data must be heavily regulated by law. Otherwise all data will be misused in the most ingenious way. I’m looking at Clearview AI now.
As a statistician I am naturally hungry for data. But I am convinced that all useful services can be implemented while respecting our individual right to our personal data.
Every data collection must be a real opt-in, not just the typical clicking through the information – nobody has time or desire to read it. The sale and re-use of data must be strongly regulated by law. Otherwise all data will be misused in the most ingenious way. I’m watching Clearview AI right now.
As a statistician I’m hungry for data, of course. But I’m convinced that any useful services can be implemented respecting our individual right on our personal data. Every data-collection must be a real opt-in, not just the typical click-through-information-nobody-has-time-or-interest-to read. Selling and reuse of data must be heavily regulated by law. Otherwise all data will be misused in the most ingenious way. See the Clearview AI case.
All in all I’m back to the first general answer. I’m optimistic!

Thank you so much for your insights and for sharing your view with us. Do you have must read recommendations for our audience for more details on statistics and AI?
Must read: Bayes Theorem on Wikipedia (example section) to get a feeling for claimed successes of algorithms
Katharina Zweig: Ein Algorithmus hat kein Taktgefühl.
Cailin O’Connor, James Owen Weatherall: The Misinformation Age: How
False Beliefs Spread
Cathy O’Neill: Weapons of Math Destruction: How Big Data Increases
Inequality and Threatens Democracy
And of course you can contact me any time at steuer@hsu-hh.de, or visit my website https://fawn.hsu-hh.de/~steuer/